
Accounting for the Basecamp 3 outage on June 27, 2022
Chicago. Monday morning, 8am. Birds are chirping. The city is getting to work. Basecamp 3 is humming along at peak performance.
In the span of the next 30 seconds, Basecamp 3 went from fully operational to severely struggling and then down entirely. It took us nearly three hours to fully restore service.
Your account data remained secure, intact, and thoroughly backed-up throughout. All told, Basecamp 3 was down for 1.7 hours. HEY, Basecamp 2, Basecamp Classic, and our other products were unaffected.
Here’s what happened, why, and what we're doing about it.
But first—
We’re deeply sorry for interrupting and delaying your work.
For many of you, this outage ate up an entire morning or afternoon on a Monday, right at the top of the week. It put some of you in the position of excusing Basecamp's reliability to your clients or colleagues as you rescheduled meetings at the last minute.
Furthermore, we're late in sharing an update. We've been sleuthing for the underlying causes of the outage so we can definitively guarantee that it won't occur again, and that's proven elusive. We're sorry to leave you hanging, wondering.
We’re leaning on your goodwill, and we will restore it.
What happened
What you saw: On Monday, June 27 at 13:00 UTC, Basecamp 3 started getting extremely slow, then started showing error pages. Some things did work but took forever, yet Basecamp 2 and Basecamp Classic were behaving normally. Then—nothing worked at all! Some minutes later, things seemed to be up & running again, only to slow down and start showing errors minutes afterward. Finally, around 15:45 UTC, Basecamp 3 was back in business and stayed that way. Here’s the incident timeline from basecampstatus.com.
What we saw: Total database gridlock. Within the span of 30 seconds, between 13:00:00 and 13:00:30 UTC, Basecamp 3’s primary database went from breathing freely to catastrophically congested. Our other apps were unaffected. We responded immediately with a series of escalating countermeasures, but plans A, B, and C each fell through, triggering entirely new errors. Eventually, plan D worked and we restored Basecamp 3 to full service at 15:49 UTC. By this point, we had clocked in 103 minutes (1.7 hours) of cumulative downtime. No data was lost.
Why it happened
Diagnosing this database overload has frustrated our efforts at root-cause analysis. We've been deep in investigation, research, and remediation, which delayed this report well past its due with the expectation that we'd find a definitive answer.
Trouble is, there’s no single, clear culprit to pin down. We’re dealing with a “tipping point” where stepping just beyond a system's limits sends it from stable to unstable in a flash.
Why didn't this happen last week, or the week before, or next week? What was different about this week? That's the nature of a tipping point: it creeps up on you. No particular difference or trigger event is needed, as much as we'd like to find one. Basecamp 3 is growing steadily and rapidly, inching the primary database ever closer to its limits, and Monday, June 27 was simply the first day that it stepped just beyond—the tipping point.
For our primary database, the cascade began with internal lock contention. We run at very high concurrency, with thousands of database connections from our Rails application servers and hundreds of execution threads vying for processing time on a very beefy many-CPU system. Databases are built to handle precisely this sort of workload. But there are limits.
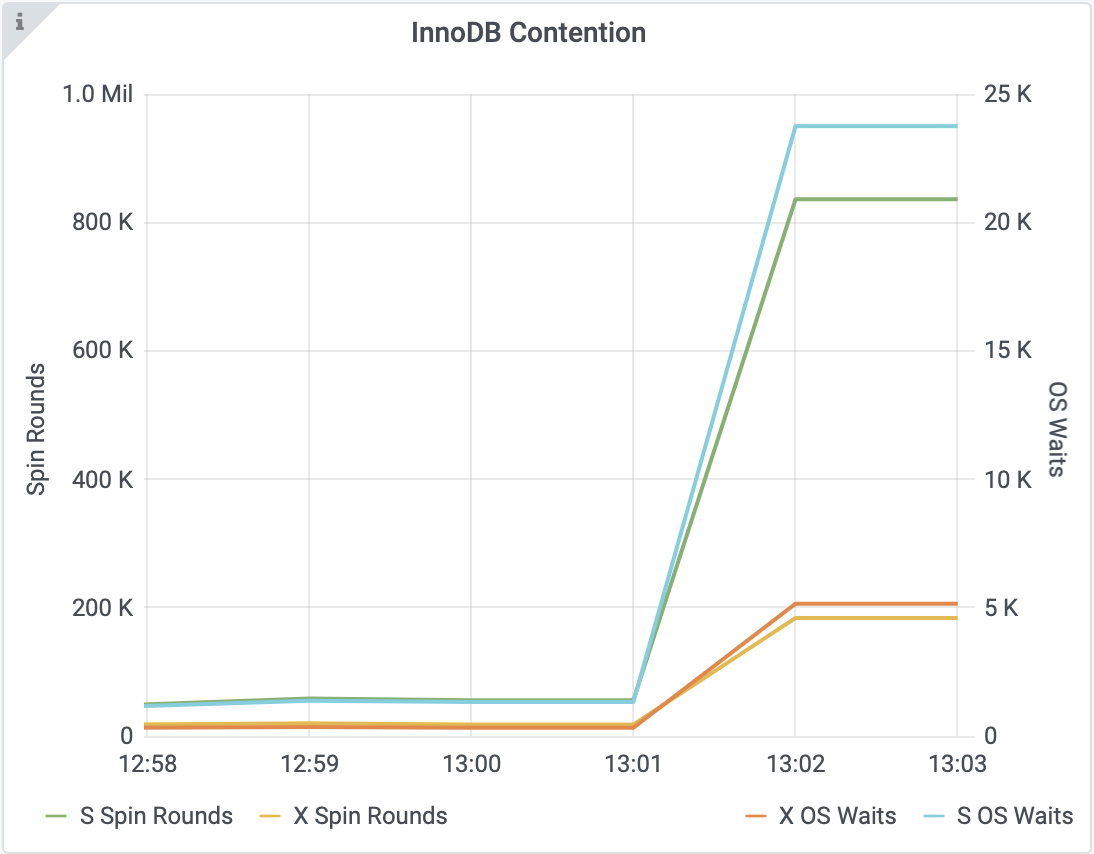

To coordinate all this activity happening in parallel, the database uses a variety of "locking" mechanisms to govern concurrent data access. Locks ensure data consistency and durability by ensuring that readers and writers proceed in an orderly manner. This is what leads to the tipping point. Locking purposefully limits concurrent operations, resulting in bottlenecks where one slow operation that's holding a lock blocks all the others who are waiting on it. Like a crowd moving single-file through an exit, and someone stops to tie their shoe on their way through the door. This cascades catastrophically when those waiting on the lock are consuming limited database resources, or even holding locks of their own that others are waiting on, causing an exponentially worsening pile-up.
This happened to the Basecamp 3 primary database. A rush of demanding database queries came in starting at 13:00 UTC, right when we send out a variety of scheduled notifications in massive batches. Those queries became a contagion, snowballing into a cascade of heavy lock contention that resulted in a bottleneck for all database queries.
Then came the real snowball: even as thousands of queries sat bottlenecked, patiently waiting their turn, thousands more new queries continued to flood in. Many of them established new database connections, resulting in spawning new threads of execution, which then bottlenecked on the same locks, magnifying the pressure on the first bottleneck and, worse, introducing new ones.
Then it was all over. The server hardware was overwhelmed with thousands of threads of execution. The database wasn't crashed or "down" in the most-technical sense, but it was effectively unable to make progress, mired down in the costs of coordinating concurrent work.
To relieve the load on the primary database, we paused and disabled parts of Basecamp 3, like delaying progress report emails until later in the day. These measures slowed the snowball, but the database was already well past overwhelmed.
Now comes the kicker. Outside of slowing the growth of the snowball, our best bet is to melt it as much as we can: terminate bottlenecked queries and let the database breathe again. But terminating queries is not so simple, since they're part of database transactions with durability guarantees. Terminating a query means rolling back the entire database transaction, which is itself a costly endeavor and… bottlenecks on the same locks. We encountered this the hard way, after terminating thousands of queries only to see the snowball grow and accelerate.
Our only option here was to "fail over:" leave the beleaguered primary database behind and switch over to a replica database waiting in the wings for just this sort of disaster. So we performed the failover, by the book. It went off without a hitch. Too easy, right? Right. Basecamp 3 came back online. We cautiously signaled an all-clear as we worked through the fallout and reenabled features we had paused. And then it tipped over again.
Breathe. Same kind of snowball this time, but dirtier and driven by a different mix of contributing factors. Yet again boiling down to high-concurrency lock contention. Alert to the gravity of the situation, we quickly put Basecamp 3 into maintenance mode and instituted hard limits on database query time. That slowed the snowball until it melted entirely.
We were back. Chastened, humbled, but back, and now doubly cautious to call a public all-clear with any confident guarantee. So we took it step by step, relying on the database query limits as guardrails as we patiently brought everything back online. That did it.
We called the all-clear at 15:49 UTC, nearly three hours after the incident began, with 103 minutes of downtime on the docket.
How we're fixing it
We went very wide and very deep to build a detailed picture of what had occurred and why, pursuing each line of inquiry in parallel. We reviewed all recent code changes in detail, analyzed application and database metrics for anomalies, constructed a simulated test environment to recreate the incident, and pored over database changelogs and bug reports.
Yet we didn't—and still don't—have the luxury of clear, single issue to fix which would 100% rule out another outage. Instead, we have a whole host of contributing factors conspiring to push us just past a tipping point. So we must walk the long, hard path: reduce risk, build confidence, and prove it.
We've employed two broad categories of technical measures to limit risk and build confidence.
1. Database, don't tip over!
This is a matter of careful tuning to better manage concurrency and limit our exposure to tipping over, ideally without affecting performance.
Setting hard limits on database queries acts as a pressure-relief valve. If normally-fast queries are slowing down beyond a certain point, we're better off letting them fail instead of waiting, piling up, and tipping over.
Tuning limits on concurrency acts as another. Beyond a certain point, the more that's running in parallel, the slower the system overall.
Establishing tighter service-level expectations. We've long tolerated "top of the hour" database load spikes as a reasonable, even unavoidable, consequence of delivering massive batches of scheduled reminders, notifications, and reports within the span of a few minutes. We're reversing course on that with a zero-tolerance policy for load spikes. We're giving this greater scrutiny, top to bottom, from product design down to database internals.
2. Basecamp, stop pushing so hard!
We ask the world of our database and it's served us impeccably over the years. As Basecamp 3 has grown, so has its demands on the database, particularly at the top of the hour when we dispatch millions of reminders and email progress reports in massive bursts. We can redistribute that load so it isn't all concentrated into a short time window and at such high concurrency.
We reduced the number of parallel workers we have performing certain scheduled jobs, decreasing database load by reducing concurrent execution and lock contention.
We allow some scheduled activities to run over the course of some minutes rather than trying to get them all done immediately, decreasing database load by spreading it out over time.
We shifted many of these "bursty" queries from the primary database over to read-only database replicas, decreasing database load by… sending it elsewhere!
We reviewed the past year of database metrics to assess whether we had any quiet regressions in performance or load that slipped past us. We found several. They hadn't tripped any alarm bells, but they did hasten our approach to this tipping point by gradually increasing primary database load. We're addressing each of these systematically.
What's next
We're in the clear now, but the work has just begun. We struggled to respond to this outage with confidence and certainty. We're very familiar with these systems, yet we found ourselves flummoxed by the lack of a single "smoking gun" and by the lack of deep visibility into database internals. This one got us good.
We can't guarantee zero outages, but we can do our absolute best to prevent them, prepare for them, and respond to them effectively. Here's where we're directing our efforts in the coming months:
We're identifying and redistributing other "bursty" activities that result in concentrated database hotspots.
We're tuning the database for more predictable behavior under heavy load and high concurrency.
We're dialing up our observability into database internal locking and transaction states.
We're introducing more ergonomic tools for selectively disabling high-load Basecamp 3 features in the heat of an incident.
We're lining up operational fire drills to practice and tune our response to a wedged database.
We're evaluating upgrading the database, both software and hardware, for scalability to match Basecamp's growth in coming years.
We're establishing service level objectives (SLOs) for the components that power Basecamp 3 for earlier, better characterized, signals about database performance changes.
We're instituting quarterly "frog in a pot" performance/load reviews to identify quiet, subtle performance changes that slip under the radar.
Thank you for being a Basecamp customer. We're very sorry we put you in the position of having to bear with us while Basecamp 3 was down just when you needed it. We're making it right.
Here we go.
—
Follow along with live Basecamp status updates at basecampstatus.com and on Twitter.
Get in touch with our fabulous support team anytime: support@basecamp.com.
Email’s new heyday
Email sucked for years. Not anymore — we fixed it. HEY’s fresh approach transforms email into something you want to use, not something you’re forced to deal with.
Try HEY free
Tried Basecamp lately?
Used an earlier version, but moved on? Heard of it, but never signed up? Today’s Basecamp will surprise you! It’s all-new, entirely modern, and unlike anything else.
Try Basecamp free